[Home]
20 使用stack和pivot实现数据透视

1.获取多维度指标数据
df_group = df.groupby([df["pdata"].dt.month,"Rating"])["UserID"].agg(pv = np.sum)
df_group.head(20)
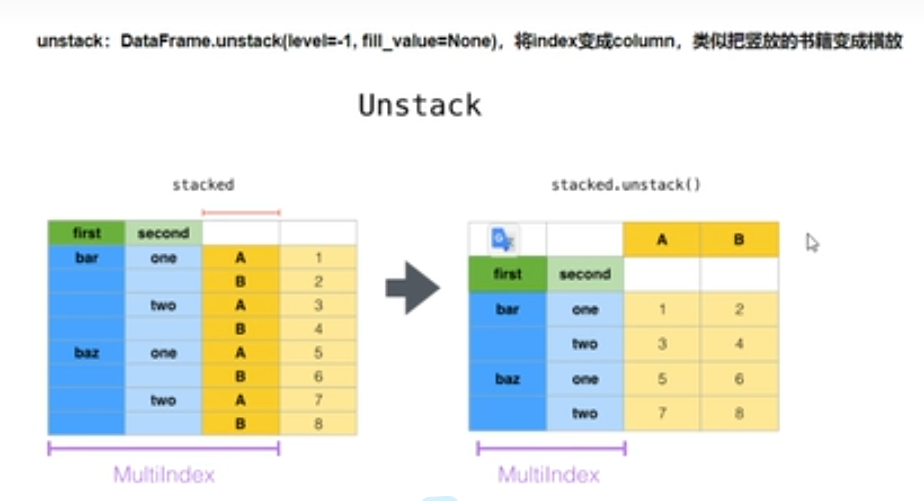
2.unstack实现二维透视
df_stack = df_group.unstack()
# unstack与stack的互逆操作
df_stack.stack().head(20)
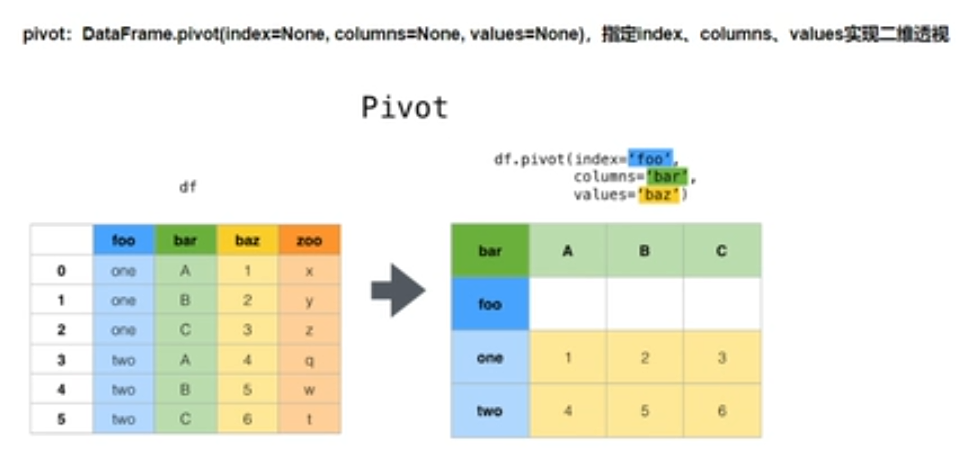
3.使用pivot简化透视
df_pivot = df_reset.pivot("pdata","Rating","pv")
#pivot方法相当于df使用set_index创建分层索引再调用unstack
4.stack\unstack\pivot使用语法
stack:

unstack:
pivot: